
「音声をテキストに変換したい」「会議の議事録作成を自動化したい」——そんな時に役立つのが、OpenAIが開発した音声認識モデル「Whisper AI」です。
本記事では、Whisper AIの特徴から使い方、ビジネスでの活用方法まで徹底解説します。
本記事でわかること:
– Whisper AIとは何か、どのような仕組みか
– Whisper APIの使い方と料金
– 日本語対応の精度と限界
– 他の文字起こしツールとの違い
– ビジネスでの活用事例
Whisper AIは、無料で使える高性能な音声認識モデルとして、開発者・ビジネスユーザーの両方から注目されています。
Whisper AIとは?基本概要
Whisper AIは、OpenAIが2022年に公開した音声認識モデルです。68万時間の多言語音声データでトレーニングされており、高い認識精度を実現しています。
Whisperの基本情報
| 項目 | 内容 |
|---|---|
| 開発元 | OpenAI |
| 公開年 | 2022年 |
| モデル種類 | 音声認識(Speech-to-Text) |
| ライセンス | MIT License(無料で利用可能) |
| 対応言語 | 99言語(日本語含む) |
Whisperの特徴
- 高精度:従来の音声認識モデルよりも高い精度
- 多言語対応:99言語に対応、翻訳も可能
- オープンソース:無料で使える
- 複数のモデルサイズ:用途に合わせて選択可能
Whisper AIの仕組みとモデル
モデルアーキテクチャ
Whisperは、Transformerベースのエンコーダ・デコーダ構造を採用しています。
- エンコーダ:音声から特徴量を抽出
- デコーダ:特徴量からテキストを生成
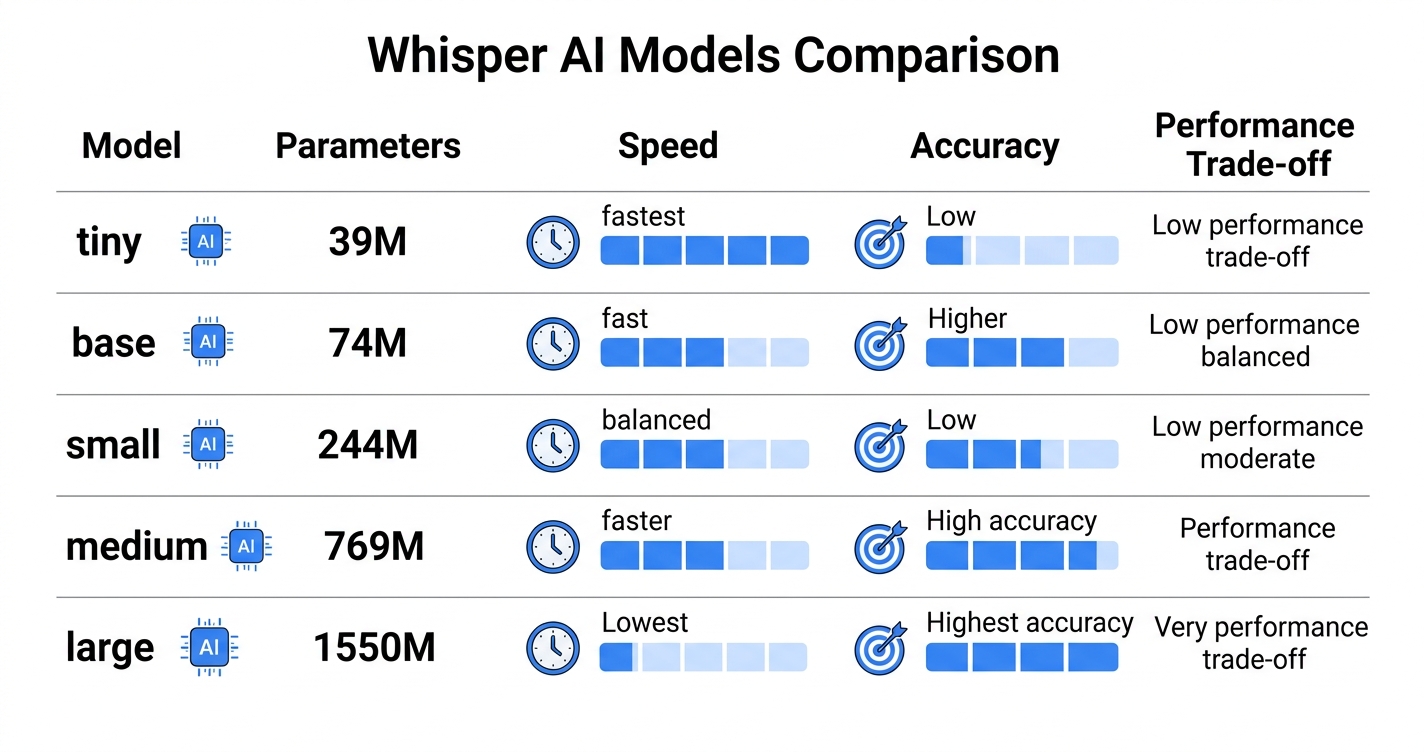
モデルサイズと用途
Whisperは5つのモデルサイズが提供されており、用途に合わせて選択できます。
| モデル | パラメータ数 | メモリ | 速度 | 精度 | おすすめ用途 |
|---|---|---|---|---|---|
| tiny | 39M | ~1GB | 最速 | 普通 | リアルタイム処理 |
| base | 74M | ~1GB | 速い | やや良い | 軽量アプリ |
| small | 244M | ~2GB | 普通 | 良い | 一般用途 |
| medium | 769M | ~5GB | 遅い | とても良い | 高精度が必要な場合 |
| large | 1550M | ~10GB | 最遅 | 最高 | 最高精度が必要な場合 |
ビジネス用途では、精度と速度のバランスが良い「small」または「medium」が推奨されます。
Whisperの能力
Whisperは以下のタスクに対応しています:
- 音声認識:音声をテキストに変換
- 翻訳:音声を英語に翻訳
- 言語識別:音声の言語を自動判定
- タイムスタンプ:単語レベルのタイミング情報
Whisper AIの使い方
方法1:Pythonで使う
ローカル環境でWhisperを使う方法です。
# インストール
pip install openai-whisper
# 基本的な使い方
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
方法2:Whisper APIを使う
OpenAIのAPI経由で使う方法です。
from openai import OpenAI
client = OpenAI()
audio_file = open("audio.mp3", "rb")
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="text"
)
print(transcript)
方法3:GUIツールを使う
プログラミング不要で使えるツールもあります:
- WhisperDesktop:Windows/Mac用デスクトップアプリ
- Aiko:macOS用の優れたWhisperクライアント
- Buzz:クロスプラットフォーム対応
Whisper APIの料金と制限
料金体系(2026年3月現在)
主要な利用方法と料金は以下の通りです:
- ローカル実行:無料(自分のPCで実行)
- Whisper API:$0.006 / 分($0.36 / 時間)
APIの制限
- 最大ファイルサイズ:25MB
- 最大ファイル長さ:制限なし(長いファイルは自動分割)
- 同時リクエスト数:プランによる
ビジネス会議の文字起こしには、専用ツールの方が便利です
Whisper AIの日本語対応
日本語認識の精度
Whisperの日本語認識は、全体的に高い精度を誇りますが、以下の点に注意が必要です。
得意なシーン:
– クリアな発音
– 静かな環境
– 標準的な話し方
– 一人の話者
苦手なシーン:
– 複数の話者が同時に発話
– 専門用語・業界用語
– 早口
– ノイズの多い環境
日本語利用のヒント
| ヒント | 効果 |
|---|---|
| 高品質の音声 | 認識精度が大幅に向上 |
| 単一話者 | 話者識別の必要がなく精度向上 |
| 適切なモデル選択 | medium/largeで高精度化 |
| 事前のノイズ除去 | 認識エラーの削減 |
Whisper AIと他の文字起こしツールの比較
主要ツール比較表
| ツール | 特徴 | 日本語 | 料金 | おすすめ用途 |
|---|---|---|---|---|
| Whisper AI | オープンソース、高精度 | ○ | 無料/API有料 | 開発者、技術者 |
| Felo Subtitles | 会議特化、リアルタイム | ◎ | $9/月〜 | ビジネス会議 |
| Notta | 日本語最適化 | ◎ | $9/月〜 | 日本語会議 |
| Otter.ai | 英語特化 | △ | $10/月〜 | 英語会議 |
| Google Cloud STT | スケーラブル | ○ | 従量課金 | 大規模処理 |
Whisperの強み
- 無料で使える:ローカル実行ならコストゼロ
- カスタマイズ可能:自分でモデルを調整できる
- プライバシー:データが自宅から外に出ない
Whisperの弱み
- 技術知識が必要:Pythonなどプログラミングスキルが必要
- リアルタイム処理が難しい:基本的にバッチ処理
- 会議機能がない:話者識別、要約などの機能が別途必要

ビジネスでのWhisper AI活用方法
活用事例1:会議の文字起こし
Whisperを使って会議録音をテキスト化できます。
ワークフロー:
1. 会議を録音
2. Whisperで文字起こし
3. テキストを要約・整理
注意点:
– リアルタイム処理は難しい
– 話者識別は別途実装が必要
– 日本語ビジネス会議では専用ツールの方が便利
活用事例2:コンテンツ制作
YouTube動画、ポッドキャストの文字起こしに活用できます。
効果:
– 字幕作成の時間短縮
– SEO対策(テキストコンテンツ化)
– コンテンツのアクセシビリティ向上
活用事例3:カスタマーサポート
通話録音の文字起こしで、品質管理や分析に活用できます。
効果:
– 通話内容の検索・分析
– トレーニングデータの作成
– コンプライアンス対応
カスタマーサポートの効率化には、AIサポートツールの比較も参考にしてください。
活用事例4:研究・学術
講義、インタビューの文字起こしに活用できます。
効果:
– 講義ノートの自動作成
– インタビューの分析
– 研究データの整理
研究・学習用途には、NotebookLMなどのAIノートツールと組み合わせるとより効果的です。

Whisper AIの限界と対策
限界1:リアルタイム処理
Whisperは基本的にバッチ処理向けで、リアルタイム文字起こしには向きません。
対策:
– リアルタイム処理が必要な場合は、Felo Subtitlesなどの専用ツールを検討
限界2:話者識別
Whisper自体には話者識別機能がありません。
対策:
– 別途話者識別ライブラリ(pyannote.audioなど)を組み合わせる
– または話者識別機能付きツールを使用
限界3:専門用語の認識
業界特有の専門用語は誤認識することがあります。
対策:
– 専門用語の辞書を作成
– ファインチューニングでモデルを調整
– 後処理で用語を正規化
ツール選びには、Notta精度比較も参考にしてください。
限界4:日本語のビジネス表現
敬語、専門的なビジネス表現は誤認識することがあります。
対策:
– 日本語特化のツールを検討
– 高精度モデル(large)を使用
– 事前に音声品質を向上させる
Whisper AIの使い方:基本ステップ
ステップ1:環境構築
# Pythonのインストール(必要な場合)
# その後、Whisperをインストール
pip install openai-whisper
ステップ2:モデルのダウンロード
最初の実行時にモデルが自動的にダウンロードされます。
import whisper
model = whisper.load_model("base") # 好きなサイズを選択
ステップ3:文字起こし実行
result = model.transcribe("audio.mp3", language="ja")
print(result["text"])
ステップ4:結果の活用
テキストデータを保存、要約、分析などに活用します。
よくある質問(FAQ)
Q1: Whisper AIは完全に無料ですか?
ローカル実行なら完全に無料です。APIを使う場合は従量課金されます。
Q2: 日本語の認識精度はどの程度ですか?
全体的に高い精度ですが、専門用語や早口には弱い面があります。ビジネス会議では専用ツールの方が安心です。
Q3: リアルタイムで文字起こしできますか?
Whisper単体では難しいです。リアルタイム処理が必要な場合は、Felo Subtitlesなどのツールがおすすめです。
Q4: どのモデルサイズを選ぶべきですか?
用途によりますが、一般用途なら「small」、高精度が必要なら「medium」がおすすめです。
Q5: 商用利用は可能ですか?
はい、MIT Licenseなので商用利用も可能です。API利用の場合はOpenAIの利用規約に従ってください。
Q6: Felo Subtitlesとの違いは?
Whisperは開発者向けの音声認識モデルですが、Felo Subtitlesはビジネス会議向けの完成されたサービスです。リアルタイム処理、話者識別、要約などの機能が含まれています。
まとめ:Whisper AIは開発者向けの強力なツール
Whisper AIは、無料で使える高性能な音声認識モデルとして、開発者や技術者に強力な選択肢を提供しています。
Whisper AIがおすすめな人:
– 音声認識を自分のアプリに組み込みたい開発者
– コストを抑えて文字起こしをしたい技術者
– カスタマイズが必要なプロジェクト
ビジネス会議には:
– リアルタイム処理が必要
– 話者識別が欲しい
– 日本語ビジネス表現に対応したい
これらのニーズには、Felo Subtitlesのような専用ツールが適しています。
用途に合わせて適切なツールを選びましょう。